Es steht vieles im Internet wie man den Speicher Pool hat aufzubauen. Aber es gibt viele verschiedene Ansätze das in der Realität umzusetzen. Ein paar Fragen sollte man vorher geklärt haben, wie zum Beispiel was möchte ich für eine Performance erreichen? Wie viel Speicherplatz benötige ich? Möchte ich meinen Speicherpool beliebig erweitern können? Wie groß sollte der Cache für L2ARC & LOG gewählt werden? Alles Fragen die vorher geklärt werden sollten, bevor man an sein Datapool Design ran geht.
Beispiel #1: Viel Speicherplatz und trotzdem schnell

In diesem Beispiel werden für den Datapool einfache und beliebig groß gewählte HDDs genommen. Diese bilden den Grundstein für meine Datenablage und werden über eine RAID-Z1 abgesichert. (Eine HDD darf ausfallen) Um das ganz zu beschleunigen kommt zum normalen ARC Cache (Lesecache) ein L2ARC Cache (Lesecache) in Form einer SSD hinzu. Das gibt uns einen deutlichen Schub in der Lesegeschwindigkeit hinsichtlich der häufig gelesenen Daten. Zusätzlich wird ein LOG Cache erstellt für hohe Schreibgeschwindigkeiten. Da in diesem Bereich produktiv geschrieben wird und wir uns auch dort vor einem Ausfall schützen sollten, wird auch dieser Bereich gespiegelt (Mirror).
Zusammengefasst haben wir einen sehr großen Speicherbereich, welcher durch sehr performante SSDs bei Lese- & Schreibprozessen unterstützt wird. Wer viel Speicherplatz benötigt, aber trotzdem fix unterwegs sein will, ist mit diesem Modell richtig unterwegs.
Beispiel #2: Volle NVMe Power
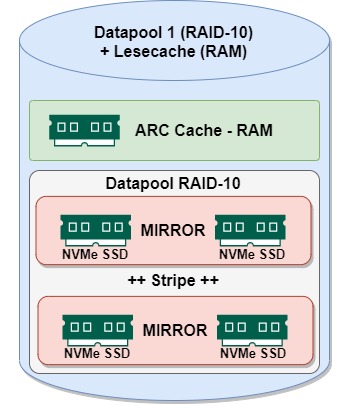
Na gut, das ist eventuell ein wenig übertrieben, aber durchaus denkbar wenn man einfach viel Performance braucht. Ob nun wie hier im Bild zusehen der richtige Weg ist ein RAID-10 zu konfigurieren oder lieber ein RAID-Z1 lassen wir mal so im Raum stehen.
Also hier kommt ein typisches RAID-10 zum Einsatz, wobei jeweils 2 NVMe SSDs im Mirror sind und diese Datenverbunde dann noch übergreifend gestriped werden. Die NVMe SSDs sind so schnell, das ein Schreibcache natürlich nicht zum Einsatz kommt. Lediglich der Lesecache ARC, welcher im RAM aufbewahrt wird, kann hier gerne groß gewählt werden. Dieser würde dann sogar noch die NVMe’s im Leseteil entlasten und Platz schaffen für noch mehr Schreibperformance. Lange Rede kurzer Sinn, denkbar ist das Konstrukt für extreme Anwendungsfälle wie Hochleistungsdatenbanken im Clusterbetrieb mit vielen hunderttausend Anfrage & Abfragen die Sekunde.
Viele weitere Informationen zu ZFS findest du hier:
ZFS erklärt: Alle Funktionen des Dateisystems im Überblick
ZFS Cache – ARC / L2ARC / LOG – ZIL // Der Performance Guide
ZFS Deduplizierung – So einfach geht Speicherplatz sparen
Habe ich etwas vergessen? Fehlen dir noch Informationen? Benötigst du trotzdem noch Hilfe bei deinem Anliegen? Dann schreib mir eine private Nachricht oder poste es hier direkt in die Kommentare.
Dennis Schröder // Geiler Typ








25. Juni 2025 um 17:48 Uhr
Kann man auch eine einzelne Partition (z.B. /dev/nvme0n1p5) als L2ARC hinzufügen oder benötigt ZFS hier Zugriff auf die ganze Platte (also /dev/nvme0n1)?